
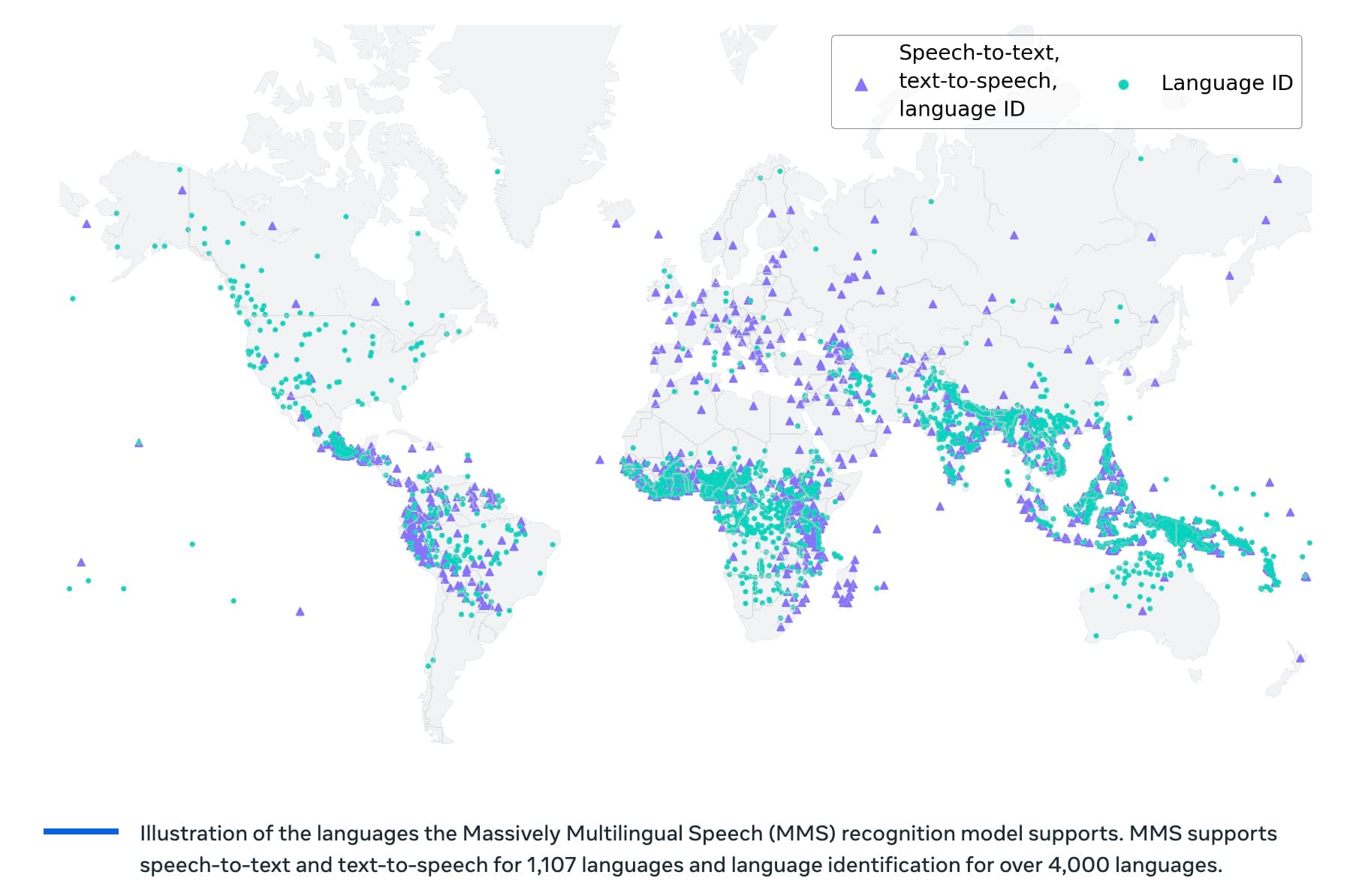
Na področju jezikovne umetne inteligence je bil ponovno narejen velik korak naprej. Pri Meta AI so predstavili nov jezikovni model (nevronsko mrežo), ki zna pretvarjati govor v besedilo in besedilo v govor za več kot 1.100 jezikov. Do sedaj so programi za prepoznavanje govora pokrivali le približno 100 jezikov, kar je predstavljalo le majhen delež od več kot 7.000 znanih jezikov, ki jih ljudje govorijo po svetu.
V okviru projekta MMS (Massively Multilingual Speech) so raziskovalci nevronsko mrežo izobrazili na novem naboru podatkov, ki vključuje označene podatke za več kot 1.100 jezikov ter neoznačene podatke za skoraj 4.000 jezikov. Med njimi so tudi jeziki, kot je Tatuyo, ki imajo le nekaj sto govorcev. Za večino teh jezikov ni obstajala še nobena govorna tehnologija.
Meta AI je javno objavil svoje modele in kodo, tako da lahko tudi drugi raziskovalci gradijo na njihovem delu. Upajo, da bodo s tem prispevali k ohranjanju velike jezikovne raznolikosti na planetu.
Zbiranje zvočnih podatkov za več tisoč jezikov je predstavljalo velik izziv, saj so največje obstoječe zbirke podatkov o govoru vključevale največ 100 jezikov. Za premagovanje tega izziva so uporabili verska besedila, kot je Sveto pismo, ki so bila prevedena v veliko jezikov. Ti prevodi vsebujejo javno dostopne zvočne posnetke ljudi, ki berejo ta besedila v različnih jezikih. V okviru projekta so ustvarili nabor podatkov o branju Nove zaveze v več kot 1.100 jezikih, kar pomeni povprečno 32 ur podatkov na jezik.
Z uporabo neoznačenih posnetkov drugih verskih branj so število razpoložljivih jezikov povečali na več kot 4.000. Čeprav so ti podatki iz specifične domene in jih pogosto berejo moški govorci, je analiza pokazala, da se modeli enako dobro obnesejo za moške in ženske glasove. Kljub temu, da je vsebina zvočnih posnetkov verske narave, analiza kaže, da to ne vpliva preveč na to, da bi model ustvaril bolj versko obarvan jezik.
Trenutno se za prepoznavanje govora, sintezo govora in identifikacijo jezika uporabljajo ločeni jezikovni modeli. Vendar raziskovalci verjamejo, da bo v prihodnosti en sam model sposoben opravljati vse te naloge in še več, kar bo omogočilo še večjo učinkovitost.
Viri in dodatne informacije
- Meta AI: Introducing speech-to-text, text-to-speech, and more for 1,100+ languages, 22. 5. 2023.













{kind=link}