
Ko so Googlovi programerji leta 2017 prišli na idejo, s katero so želeli izboljšati kakovost strojnega prevajanja, si verjetno niso predstavljali, da bo njihova zamisel čez nekaj let povzročila pravo revolucijo na področju umetne inteligence. V tehničnem članku z nenavadnim naslovom Pozornost je vse, kar potrebujete so opisali novo obliko nevronske mreže, ki je bila posebej prilagojena za učenje jezikov.
Glavna značilnost te nevronske mreže, ki so jo poimenovali transformer, je bila, da v matematični zapis ni zakodirala le pomena posameznih besed, ampak tudi kontekst, v katerem so bile besede uporabljene. Nevronska mreža se je tako lahko lažje naučila, katere besede so medsebojno odvisne oziroma katere zahtevajo več pozornosti v posamezni situaciji.
Da bi lahko razumeli, kako delujejo na transformerjih osnovani sistemi umetne inteligence, kot je chatGPT, čeprav za prevajanje in vrednotenje vsebin podobne sisteme uporabljata tudi google in facebook, moramo najprej pojasniti, kaj sploh so nevronske mreže in kako se učijo izvajati najrazličnejša inteligentna opravila.
Računalnike lahko zlahka naučimo izvrševati najrazličnejše naloge, ki jih znamo opisati v obliki algoritmov oziroma zelo natančnih navodil. Vendar vseh nalog, ki jih lahko opravljamo ljudje, ni mogoče zlahka opisati v obliki algoritmov, ki jih lahko razumejo računalniki. Med opravili, ki jih ni mogoče preprosto pretvoriti v zaporedje računalniških ukazov, so tudi najrazličnejše jezikovne naloge. A v primerih, ko algoritma ne znamo napisati sami, nam lahko pomagajo nevronske mreže, ki niso nič drugega kot računalniški programi, ki znajo algoritem na osnovi učenja ustvariti sami.
Nevronsko mrežo si najlažje predstavljamo kot matematično enačbo z veliko parametri, ki jo želimo naučiti, da bo znala izvesti neko nalogo. Ko vanjo vstavimo podatke v matematični obliki, zna izračunati odgovor, česar se postopno nauči na podlagi strojnega učenja. Zelo poenostavljeno povedano, strojno učenje poteka tako, da imajo parametri nevronske mreže sprva naključne vrednosti, nato pa jih sistematično prilagajamo na način, da zmanjšujemo razliko med izračunanim odgovorom nevronske mreže in pravilno rešitvijo naloge. Za učinkovito strojno učenje zato potrebujemo veliko pravilno rešenih nalog, hitre računalnike in primerne programe, ki se znajo učiti.
Besedila nevronske mreže obravnavajo tako, da besede najprej zakodirajo oziroma pretvorijo v številke, s katerimi lahko računajo. Osnovna operacija, ki se je poskušajo naučiti za jezikovne naloge prilagojene nevronske mreže, je napovedovanje naslednje besede v besedilu. Posamezno serijo besed v učnem gradivu najprej pretvorimo v številke, nato pa nevronska mreža glede na svoje trenutne nastavitve parametrov izračuna napoved naslednje besede v zaporedju. Po številnih ponovitvah izračunamo napako napovedi in na tej osnovi prilagodimo parametre, da se napaka v povprečju zmanjšuje. Postopek učenja ponavljamo, dokler ne zna nevronska mreža zanesljivo napovedati naslednje besede v zaporedju.
Za učenje uporabljamo kar besedila, ki so dostopna na spletu, iz katerih poskušamo odstraniti dele, ki jih prežema sovraštvo ali so polni najrazličnejših predsodkov. Doseči želimo namreč, da bi se umetna inteligenca naučila spoštljivega sporazumevanja, ne pa groženj, preklinjanja in zmerjanja.
Vendar ob zaključku prve faze učenja (pre-training) še ne dobimo jezikovnega modela, ki bi znal smiselno odgovarjati na vprašanja in kramljati z uporabnikom. V tej fazi smo s predhodnim učenjem ustvarili le algoritem, ki zna na podlagi odlomka iz besedila izračunati najbolj smiselno naslednjo besedo v zaporedju. Če mu kot vhodni podatek postavimo vprašanje, se bo morda odzval z dopolnitvijo vprašanja, ne nujno s smiselnim odgovorom.
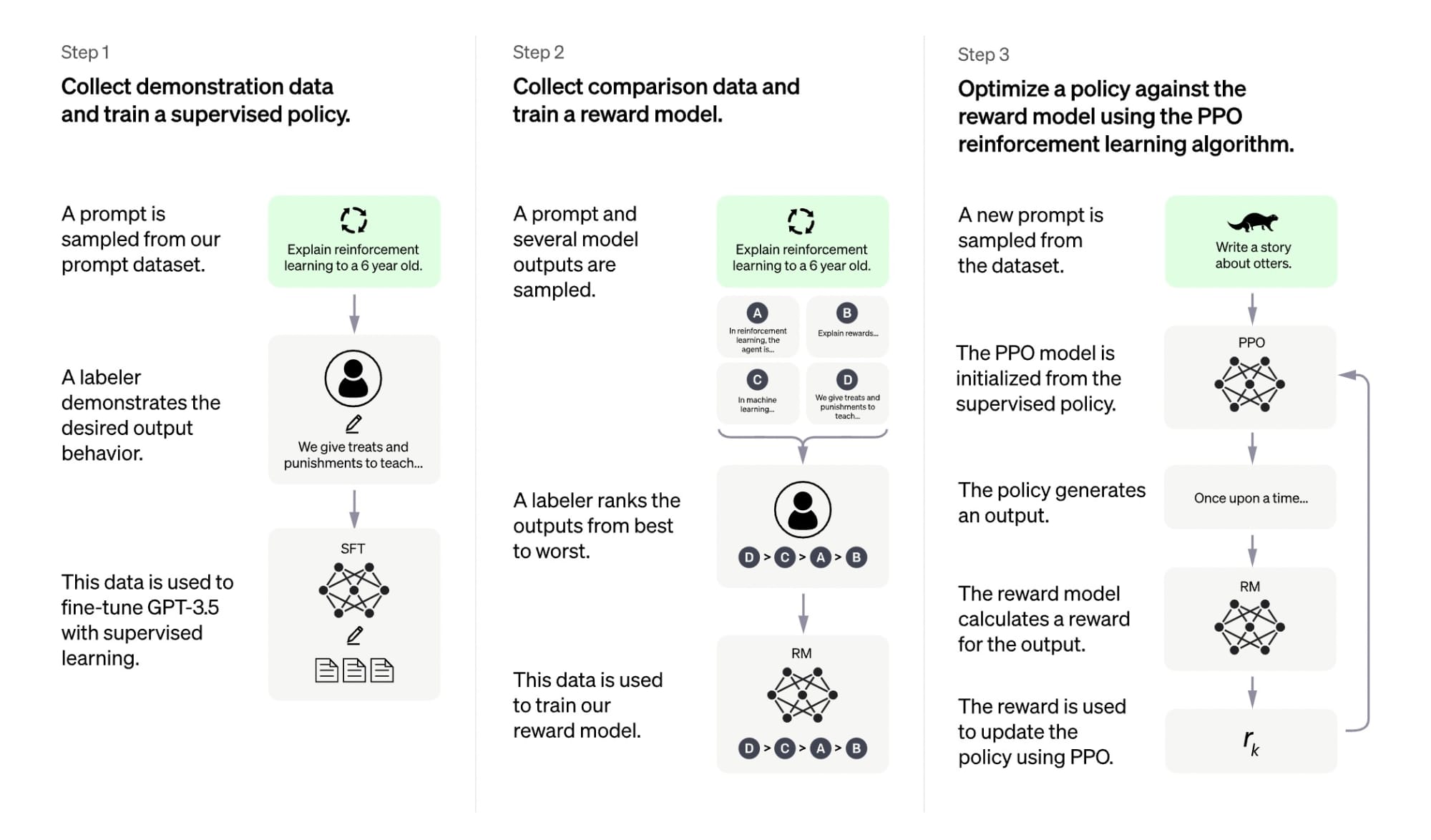
Zato moramo v naslednjem koraku nevronsko mrežo, ki ima zdaj že občutek za jezik, naučiti še, da bo znala smiselno izpolnjevati naloge, kot je odgovarjanje na vprašanja. V postopku, ki se mu reče natančno prilagajanje (fine-tuning), moramo nevronsko mrežo naučiti, kako naj se odziva na konkretne naloge. Pripravimo ji veliko parov vprašanj z znanimi odgovori in na podoben način, kot smo prej ocenjevali ustreznost izračunane naslednje besede v zaporedju, zdaj ocenjujemo ustreznost daljšega odgovora. Na podlagi razlik med pravilnimi in izračunanimi odgovori dodatno prilagajamo parametre nevronske mreže, da so napake vse manjše.
Ena od izboljšav pri ustvarjanju chatGPT je bila, da je razvijalcem uspelo za ocenjevanje ustreznosti odgovorov izuriti dodatno ločeno nevronsko mrežo. Ta se je na ocenah odgovorov, ki so jih posredovali ljudje, naučila samodejno presojati kakovost in ustreznost ustvarjenih besedil, kar je omogočilo, da se zdaj lahko s strojem pogovarjamo na skoraj enak način kot s človekom.
Ker bodo jezikovna orodja postajala vse zmogljivejša, je pomembno, da se jih naučimo smiselno uporabljati. Morda je poučna primerjava z Wikipedijo, ki je nekoč sprožala polemike, saj naj bi bila nezanesljiva, ker je ne ustvarjajo strokovnjaki. Danes vemo, da so besedila v Wikipediji praviloma povzeta po zanesljivih virih, zato predstavljajo zelo dobro izhodišče za osnovno seznanjanje s posamezno tematiko, hkrati pa se tudi zavedamo, da Wikipedije ne smemo navajati kot vira, ampak moramo zanesljivost zapisanega še dodatno preveriti.
Podobno velja tudi za nove storitve jezikovne umetne inteligence. Nova orodja, kot je chatGPT, so zelo uporabna, a na koncu smo še vedno mi sami odgovorni za besedila, ki jih ustvarimo z njihovo pomočjo.
https://www.delo.si/mnenja/kolumne/kako-deluje-chatgpt/





")


")
")
")



{kind=link}
Ko pa je Stephen C. Kleene, matematik in princetonski diplomant, pred več kot 70 leti ustvaril ‘matematično logiko’, ki jo je poimenoval ‘Regular expressions’ (‘Regex’), si najbrž ni predstavljal, da bo kombiniranje vsakršnih številčnih vzorcev mnogo let kasneje postalo eden od evangelijev, stebrov, sicer že od antike obstoječe religije, ki slavi mehaničnega boga z imenom ‘Deus ex Machina’, saj je računal tudi na to, da je vpliv vsakršne religije obratno sorazmeren z kolektivno erudicijo potencialnih vernikov, na kar vsaj (nekatere) prebivalce Rima še opominja kip Giordana Bruna, ki dominira na tistem rimskem trgu blizu Panteona, ex ‘templja vseh bogov’, ki… Beri dalje »
Googlova Chat konkurenca Bard (zgoraj sem napačno napisal ime, Claude je precej starejši) pa je, še preden so ga dobro (uradno) lansirali že zapravil 140 milijard evrov Googletovih delnic (indeks je trenutno -7,4%), vsaj tako pravi tehnološka borza Nasdaq. Seveda je tu kup nejasnosti z bilijoni in milijardami, meni pa se niti ne ljubi raziskovati ali gre za 10 na deveto, na dvanajsto ali celo na petnajsto potenco. Te cifre so ponavadi povsem odvisne od erudicije tistega, ki jih je pač slišal, uporabil ali zapisal. AI nesojeni bard, imenovan Bard, je sicer opisan kot ‘eksperimentalna konverzacijska usluga, ki lahko pomaga… Beri dalje »
Tale štorija z umetno inteligenco dobiva že nekam bizarne in ‘kontraproduktivne’ razsežnosti, ne bi pa mogel reči, da me karkoli kakorkoli preseneča. Možgani in inteligenca so precej bolj zapleteni in kompleksni, kot npr. (umetni) udi, kolki, srce … ki so kljub vsemu, nekakšen uporaben tujek v telesu, ki ne skrbi za njihovo vzdrževanje in delovanje; slednje sicer počne v omejenem obsegu. Vsekakor pa je treba najprej poznati njihovo delovanje, nevrologija in computer znanost pa se pogosto prepletata. Alan Turing in sodelavci so (zgolj) z statistiko in predikcijo natančno rekonstruirali delovanje nacističnega šifrirnega stroja, ki so ga prvič videli šele po… Beri dalje »